文章标题 原创 翻译 转载 文章内容 客户端服务端网络交互的时候最常用的就两种通信方法:请求应答和推送,在这两种场景同时存在的情况下客户端怎样保证与服务端的数据实时保持一致。 客户端可以分页请求服务端数据,同时为了保证数据实时更新还需要接收推送,将推送的数据更新到客户端缓存中。这样请求应答的就是一个整体数据(虽然是分页的),而推送就是一个局部更新的过程,当缓存数据有问题的时候做一下请求应答就可以了(类似如刷新的过程)。 # 为什么要推送的版本号 我们知道推送的是局部数据,客户端收到的推送可能丢失也有可能重复,有了版本号客户端才可以判断推送的消息是否完整,以及在出错的情况下进行补救,服务端每次推送版本号加1。 需要注意的是这种版本号并不是某个数据的一部分,并不存在于数据库的某条数据中,它随着业务数据的变动而不断递增,它是一个临时的存在于缓存中的变量。 # 客户端接收推送消息版本号处理 客户端收到推送消息后,通常有以下情况要处理: * 版本号连续,推送的版本号等于本地缓存版本号加1,这种情况下正常处理就可以了; * 版本号重复,推送的版本号小于或者等于本地缓存版本号,应该丢弃推送; * 版本号缺失,此时要进行补差处理,补差完成后才能继续处理推送否则会乱序; # 服务端推送消息 服务端为什么要推送消息,那是因为服务端数据有变化(增删改了某些数据),服务端将这些操作数据推送出来告诉客户端要更新数据了。如果更新的数据量比较大的情况下,就不适合推送所有变动的数据了,直接告诉客户端一个同步的信号,让客户端重新拉取一下最新数据就可以了。 由于客户端会补差推送的数据,所以服务端必须缓存部分最近的推送的消息(缓存多少要根据实际业务频率、数据量来决定),如果补差不到的话,客户端只能请求最新的整体数据了。 # 请求应答和推送带来的问题 首先明确一个概念,请求应答的是整体数据,推送的是局部数据。大致流程图如下: 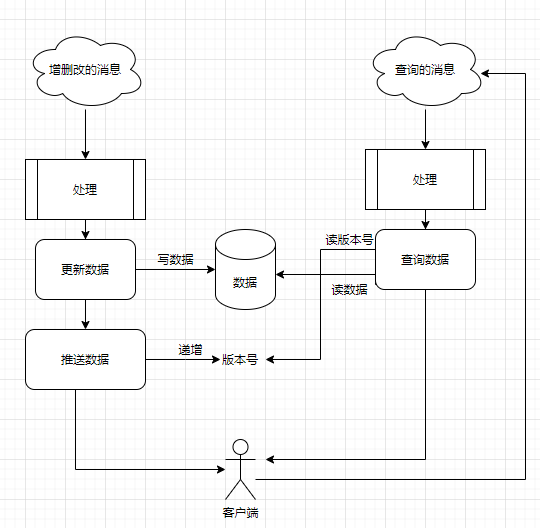 ## 问题一 其中关键点就是读写数据和读写版本号的顺序问题,为了提高效率这两个步骤并不是一个原子操作,所以在读数据和读版本号的中间,插入了写数据和写版本号,会造成客户端拿到的是老数据新版本号。 解决方法,服务端操作顺序: ``` 写:先写数据 -> 再递增版本号 读:先读版本号 -> 再读数据 ``` 这样客户端拿到的只可能是老的版本号才有补救的措施。 ## 问题二 请求应答和推送是两个通道,当客户查询数据时在服务端拿到的版本是100,但是推送的消息更快被收到的版本号是101时,由于查询的是整体数据,这个时候会覆盖掉缓存的数据,此时101这个推送的消息就会丢失。 解决方法: 此时要么再去请求一下,要么把101这个消息再补一下,如果是本地补差的话需要缓存推送的消息。 文章类别 Python Mobile Android Java Shell Life Database Bug Windows IOS Tools Boost Node.js Mac Product Tips C/C++ Golang Javascript React Qt MQ MongoDB Design Web Linux LLM ChatGPT RAG AI 提交
