在《为什么RAG很重要》一文中,我表达了对检索增强生成(Retrieval-Augmented Generation,RAG)作为私密、离线、去中心化LLM应用的关键技术的支持。当你为自己构建一样东西时,你是独自战斗的。你可以从头开始构建,但使用现有的框架会更高效。
据我所知,目前有两种选择,针对不同的范围:
- LangChain,一个用于开发LLM相关内容的通用框架。
- LlamaIndex,一个专门用于构建RAG系统的框架。
选择一个框架是一项重大投资。你希望选择一个拥有强大维护者和活跃社区的框架。幸运的是,这两个选择都在去年进行了整合,因此它们的规模是可以量化的。以下是它们的比较数据:
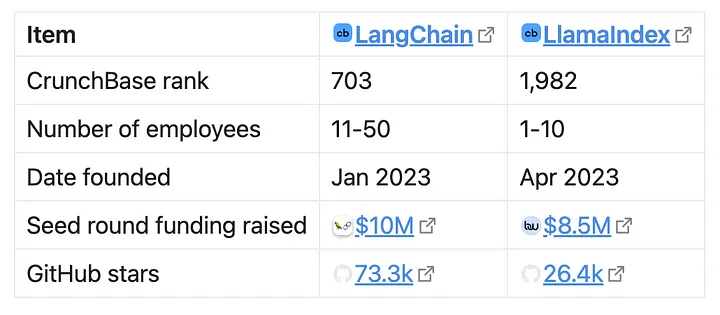
从财务数据来看,尽管LlamaIndex的目标市场要小得多(使用GitHub stars作为社区兴趣的近似指标),但它的资金金额接近LangChain,显示出LlamaIndex具有更好的生存机会。然而,LangChain提供了更多面向企业的产品,可以产生收入(比如LangServe、LangSmith等),所以这个论点可能会反过来。从金钱的角度来看,这是一个艰难的决策。
我的金融知识只能帮我到这里。让我们转向我真正擅长的领域,用Python来讨论。在这篇文章中,我将同时使用这两个框架完成一些基本任务。通过并排展示代码片段,我希望能帮助你更明智地决定在你自己的RAG聊天机器人中使用哪个框架。
创建一个使用本地LLM的聊天机器人
对于要实现的第一个任务,我选择创建一个仅在本地运行的聊天机器人。这是因为在学习使用这些框架时,我不想为模拟聊天消息付费云服务。
我选择将LLM保持在独立的推理服务器中运行,而不是每次运行脚本时都将多GB的模型加载到内存中。这样可以节省时间并避免磁盘的磨损。
虽然有多种LLM推理的API模式,但我选择了与OpenAI兼容的模式,这样它最接近官方的OpenAI端点。
以下是使用LlamaIndex实现的方法:
from llama_index.llms import ChatMessage, OpenAILike
llm = OpenAILike(
api_base="http://localhost:1234/v1",
timeout=600, # secs
api_key="loremIpsum",
is_chat_model=True,
context_window=32768,
)
chat_history = [
ChatMessage(role="system", content="You are a bartender."),
ChatMessage(role="user", content="What do I enjoy drinking?"),
]
output = llm.chat(chat_history)
print(output)
以下是使用LangChain实现的方法:
from langchain.schema import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
openai_api_base="http://localhost:1234/v1",
request_timeout=600, # secs, I guess.
openai_api_key="loremIpsum",
max_tokens=32768,
)
chat_history = [
SystemMessage(content="You are a bartender."),
HumanMessage(content="What do I enjoy drinking?"),
]
print(llm(chat_history))
在这两种框架中,API密钥可以是任意的,但必须存在。我猜这是因为在这两个框架的底层都运行了OpenAI SDK,这是一个要求。
- LangChain区分了可聊天的LLM(ChatOpenAI)和仅完成的LLM(OpenAI),而LlamaIndex通过构造函数中的is_chat_model参数来控制它。
- LlamaIndex区分了官方的OpenAI端点和OpenAILike端点,而LangChain通过openai_api_base参数来确定请求发送到哪里。
- 虽然LlamaIndex使用role参数为聊天消息打上标签,而LangChain使用单独的类。
到目前为止,这两个框架看起来并没有太大的区别。让我们继续。
构建一个用于本地文件的RAG系统
有了连接的LLM,我们可以开始工作了。现在让我们构建一个简单的RAG系统,它从一个本地文件夹中读取文本文件。以下是使用LlamaIndex实现这一目标的方法,主要参考了官方文档:
from llama_index import ServiceContext, SimpleDirectoryReader, VectorStoreIndex
service_context = ServiceContext.from_defaults(
embed_model="local",
llm=llm, # This should be the LLM initialized in the task above.
)
documents = SimpleDirectoryReader(
input_dir="mock_notebook/",
).load_data()
index = VectorStoreIndex.from_documents(
documents=documents,
service_context=service_context,
)
engine = index.as_query_engine(
service_context=service_context,
)
output = engine.query("What do I like to drink?")
print(output)
在LangChain中,代码行数会翻倍,但仍然可以处理:
from langchain_community.document_loaders import DirectoryLoader
# pip install "unstructured[md]"
loader = DirectoryLoader("mock_notebook/", glob="*.md")
docs = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
from langchain_community.embeddings.fastembed import FastEmbedEmbeddings
from langchain_community.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=splits, embedding=FastEmbedEmbeddings())
retriever = vectorstore.as_retriever()
from langchain import hub
# pip install langchainhub
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
from langchain_core.runnables import RunnablePassthrough
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm # This should be the LLM initialized in the task above.
)
print(rag_chain.invoke("What do I like to drink?"))
这些片段清楚地展示了这两个框架之间不同的抽象级别。LlamaIndex使用一个方便的名为“query engines”的软件包将RAG流水线封装起来,而LangChain则让你接触到内部组件。这些组件包括用于检索文档的连接器,以及模板提示,如“基于X,请回答Y”,以及链本身(在上面的LCEL中显示)。
这种缺乏抽象对学习者产生了影响:使用LangChain构建时,你必须在第一次尝试时就知道自己想要什么。例如,比较一下from_documents的调用位置。LlamaIndex允许你在不明确选择存储后端的情况下玩弄向量存储索引,而LangChain似乎建议你立即选择一种实现方式。(在使用LangChain从文档创建向量索引时,似乎每个人都明确选择了后端。)我不确定在遇到可扩展性问题之前,在选择数据库时是否做出了明智的决策。
更有趣的是,尽管LangChain和LlamaIndex都提供了类似Hugging Face Hub的云服务(即LangSmith Hub和LlamaHub),但LangChain将其推到了极致。请注意LangChain中的hub.pull调用。它只下载一个短小的文本模板,内容如下:
你是一个用于问答任务的助手。使用以下检索到的上下文片段来回答问题。如果你不知道答案,只需说不知道即可。答案应尽量简洁,最多三个句子。
问题:{question}
上下文:{context}
答案:
虽然这确实鼓励与社区分享优雅的提示,但我觉得这有点过头了。存储约1kB的文本并不能真正证明使用网络调用进行拉取的必要性。我希望下载的资源会被缓存起来。
将两者结合起来:一个启用了RAG的聊天机器人
到目前为止,我们构建的东西并不是很智能。在第一个任务中,我们构建了一个可以维持对话但并不了解你的东西;在第二个任务中,我们构建了一个了解你但不保留聊天历史的东西。让我们将这两个结合起来。
使用LlamaIndex,只需要将as_query_engine替换为as_chat_engine,就可以实现这一点:
# Everything from above, till and including the creation of the index.
engine = index.as_chat_engine()
output = engine.chat("What do I like to drink?")
print(output) # "You enjoy drinking coffee."
output = engine.chat("How do I brew it?")
print(output) # "You brew coffee with a Aeropress."
使用LangChain,我们需要详细说明一些事情。按照官方教程的步骤,让我们首先定义内存:
# Everything above this line is the same as that of the last task.
from langchain_core.runnables import RunnablePassthrough, RunnableLambda
from langchain_core.messages import get_buffer_string
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
from langchain.memory import ConversationBufferMemory
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import format_document
from langchain_core.prompts import ChatPromptTemplate
memory = ConversationBufferMemory(
return_messages=True, output_key="answer", input_key="question"
)
这是计划:
- 在LLM的回合开始时,我们从内存加载聊天历史记录。
load_history_from_memory = RunnableLambda(memory.load_memory_variables) | itemgetter(
"history"
)
load_history_from_memory_and_carry_along = RunnablePassthrough.assign(
chat_history=load_history_from_memory
)
- 我们要求LLM将问题与上下文结合起来:“在考虑聊天历史的情况下,我应该在笔记中寻找什么来回答这个问题?”
rephrase_the_question = (
{
"question": itemgetter("question"),
"chat_history": lambda x: get_buffer_string(x["chat_history"]),
}
| PromptTemplate.from_template(
"""You're a personal assistant to the user.
Here's your conversation with the user so far:
{chat_history}
Now the user asked: {question}
To answer this question, you need to look up from their notes about """
)
| llm
| StrOutputParser()
)
(我们不能简单地将两者连接起来,因为在对话过程中话题可能已经发生了变化,使得聊天记录中的大部分语义信息变得无关紧要。)
- 我们运行RAG流程。请注意,我们通过暗示“作为用户,我们将自己查找笔记”,来欺骗LLM,但实际上我们现在要求LLM来承担重任。我感到有点不好意思。
retrieve_documents = {
"docs": itemgetter("standalone_question") | retriever,
"question": itemgetter("standalone_question"),
}
- 我们询问LLM:“以检索到的文档为参考(以及-可选地-迄今为止的对话),你对用户最新的问题会有什么回答?”
def _combine_documents(docs):
prompt = PromptTemplate.from_template(template="{page_content}")
doc_strings = [format_document(doc, prompt) for doc in docs]
return "\n\n".join(doc_strings)
compose_the_final_answer = (
{
"context": lambda x: _combine_documents(x["docs"]),
"question": itemgetter("question"),
}
| ChatPromptTemplate.from_template(
"""You're a personal assistant.
With the context below:
{context}
To the question "{question}", you answer:"""
)
| llm
)
- 我们将最终的回答附加到聊天历史中。
# Putting all 4 stages together...
final_chain = (
load_history_from_memory_and_carry_along
| {"standalone_question": rephrase_the_question}
| retrieve_documents
| compose_the_final_answer
)
# Demo.
inputs = {"question": "What do I like to drink?"}
output = final_chain.invoke(inputs)
memory.save_context(inputs, {"answer": output.content})
print(output) # "You enjoy drinking coffee."
inputs = {"question": "How do I brew it?"}
output = final_chain.invoke(inputs)
memory.save_context(inputs, {"answer": output.content})
print(output) # "You brew coffee with a Aeropress."
这是一次非常有意义的旅程!我们学到了很多关于如何构建基于LLM的应用程序的知识。特别是,我们多次利用LLM的能力,让它扮演不同的角色:一个查询生成器,一个总结检索到的文档的人,最后成为我们对话的参与者。我也希望您现在对LCEL有足够的了解和熟悉了。
升级到代理
如果将与您交谈的LLM角色视为一个人,那么RAG流水线可以被看作是这个人使用的工具。一个人可以拥有多个工具,LLM也可以如此。您可以为它提供搜索谷歌、查阅维基百科、查看天气预报等工具。通过这种方式,您的聊天机器人可以回答关于其直接知识范围之外的事物的问题。
工具不一定局限于信息类。通过为我们的LLM提供搜索互联网、下订单购物、回复电子邮件等工具,您可以使其能够影响现实并对世界产生影响。
拥有多个工具意味着需要决定使用哪些工具以及以何种顺序使用。这种能力被称为”代理”。具有代理能力的LLM角色因此被称为”代理人”。
赋予LLM应用程序代理能力有多种方式。最通用的模型(因此也适合自托管)的方式可能是ReAct范例,我在之前的文章中稍微介绍了一下。
在LlamaIndex中实现这一点,
# Everything above this line is the same as in the above two tasks,
# till and including where `notes_query_engine` is defined.
# Let's convert the query engine into a tool.
from llama_index.tools import ToolMetadata
from llama_index.tools.query_engine import QueryEngineTool
notes_query_engine_tool = QueryEngineTool(
query_engine=notes_query_engine,
metadata=ToolMetadata(
name="look_up_notes",
description="Gives information about the user.",
),
)
from llama_index.agent import ReActAgent
agent = ReActAgent.from_tools(
tools=[notes_query_engine_tool],
llm=llm,
service_context=service_context,
)
output = agent.chat("What do I like to drink?")
print(output) # "You enjoy drinking coffee."
output = agent.chat("How do I brew it?")
print(output) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."
请注意,对于我们后续的问题”如何冲咖啡”,代理人的答案与仅仅作为查询引擎时的答案有所不同。这是因为代理人可以自行决定是否从我们的笔记中查找。如果他们对回答问题感到足够自信,代理人可能选择不使用任何工具。我们的问题”如何…”可以有两种解释方式:一种是关于通用选项,另一种是关于事实回忆。显然,代理人选择了前一种方式理解问题,而我们的查询引擎(负责从索引中查找文档)则必须选择后一种方式。
有趣的是,代理人是LangChain决定提供高级抽象的一个使用案例:
# Everything above is the same as in the 2nd task, till and including where we defined `rag_chain`.
# Let's convert the chain into a tool.
from langchain.agents import AgentExecutor, Tool, create_react_agent
tools = [
Tool(
name="look_up_notes",
func=rag_chain.invoke,
description="Gives information about the user.",
),
]
react_prompt = hub.pull("hwchase17/react-chat")
agent = create_react_agent(llm, tools, react_prompt)
agent_executor = AgentExecutor.from_agent_and_tools(agent=agent, tools=tools)
result = agent_executor.invoke(
{"input": "What do I like to drink?", "chat_history": ""}
)
print(result) # "You enjoy drinking coffee."
result = agent_executor.invoke(
{
"input": "How do I brew it?",
"chat_history": "Human: What do I like to drink?\nAI: You enjoy drinking coffee.",
}
)
print(result) # "You can use a drip coffee maker, French press, pour-over, or espresso machine."
尽管我们仍然需要手动管理聊天记录,但与创建RAG链相比,创建一个代理人要容易得多。create_react_agent和AgentExecutor在底层完成了大部分的连接工作。
总结:
LlamaIndex和LangChain是构建LLM应用程序的两个框架。虽然LlamaIndex专注于RAG用例,但LangChain似乎更广泛被采用。但在实践中,它们有何区别?在本文中,我比较了这两个框架在完成四个常见任务时的表现:
- 连接到本地LLM实例并构建聊天机器人。
- 对本地文件进行索引并构建RAG系统。
- 结合以上两者,制作具有RAG功能的聊天机器人。
- 将聊天机器人转换为代理人,以便它可以使用更多工具并进行简单推理。
希望这些比较能帮助您为LLM应用程序做出明智的选择。祝您在构建自己的聊天机器人的过程中好运!
翻译from:https://lmy.medium.com/comparing-langchain-and-llamaindex-with-4-tasks-2970140edf33